WGAN-GP - Tensorflow/Keras Implementation
논문 WGAN-GP : Improved Training of Wasserstein GANs에 대한 tensorflow 코드 구현 입니다.
구현은 논문 4 페이지에 있는 아래의 Algorithm 1을 참고하였습니다.

이제 코드와 함께 설명을 하도록 하겠습니다.
- 학습은 가상환경의 jupyter notebook 에서 진행했습니다!
- 포스트 하단에 dependency에 대한 내용이 있습니다!
Module Import
tensorflow, keras, numpy 등 필요한 모듈을 불러옵니다.
import tensorflow as tf
import tensorflow.keras as keras
from tensorflow.keras import layers, Model
#import tensorflow.keras.preprocessing.image as prep
from tensorflow.keras.datasets import mnist
from tensorflow.keras import backend as K
import os
import time
import random
import numpy as np
import matplotlib.pyplot as plt
from models import Generator_mnist, Discriminator_mnist
from data_load import get_npdata, get_data_list, load_celeba_to_np
from IPython import display
Set Parameter
알고리즘을 보면 parameter 값으로 gradient penalty coefficient ($\lambda$) = 10, $n$critic = 5, learning rate ($\alpha$) = 0.0001, adam hyperparameters $\beta$1, $\beta$2 = 0, 0.9 를 사용했습니다. batch size ($m$) = 64로 이전 wgan 구현 포스트와 동일한 값으로 설정했습니다.
따라서 같은 값으로 parameter들을 설정합니다.
learning_rate = 0.0001 # alpha
gp_lambda = 10 # gradient penalty coefficient
n_critic = 5
b_1 = 0 # Adam arg beta1
b_2 = 0.9 # Adam arg beta2
epochs = 50
batch_size = 64
noise_dim = 100
num_examples_to_generate = 16
BUFFER_SIZE = 60000 # mnist buffer size
Data Load
데이터셋은 mnist dataset을 사용했습니다.
(train_images, _), (_, _) = mnist.load_data()
train_images = train_images.reshape(train_images.shape[0], 28, 28, 1).astype('float32')
train_images = (train_images - 127.5) / 127.5 # image normalization [-1, 1]
train_dataset = tf.data.Dataset.from_tensor_slices(train_images).shuffle(BUFFER_SIZE).batch(batch_size)
mnist dataset은 숫자 0~9까지 60000개의 (28, 28, 1) shape을 갖는 흑백 이미지입니다. WGAN을 학습할 때 train label, validation set은 필요하지 않으므로 _ 로 사용하지 않음을 표시해줍니다.
불러온 6만장의 train_images는 (60000, 28, 28)의 shape을 하고 있으므로 마지막에 채널을 추가하기 위해 (60000, 28, 28, 1)의 shape으로 reshape을 합니다. Generator의 마지막 activation function을 tanh로 사용했기에 image의 값을 [-1, 1]로 normalization 해줍니다.
이렇게 얻어진 train_images를 tensorflow에서 지원하는 tf.data.Dataset을 사용해 batch 별로 Dataset object를 만들어줍니다.
Model(G, D) Load & Summary
models.py에서 불러온 model들을 확인해봅시다. 각 model들은 클래스 형태로 network을 구성하였습니다. model에 적절한 size의 Input을 넣고 model을 summary 합니다.
# model load
G = Generator_mnist()
D = Discriminator_mnist()
input1 = keras.Input(shape=(100))
input2 = keras.Input(shape=(28, 28, 1))
x1 = G(input1)
x2 = D(input2)
G.summary()
D.summary()
Models Summary 결과 입니다.
Results of Generator
Model: "generator_mnist"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 12544) 1266944
_________________________________________________________________
batch_normalization (BatchNo (None, 12544) 50176
_________________________________________________________________
reshape (Reshape) (None, 7, 7, 256) 0
_________________________________________________________________
conv2d_transpose (Conv2DTran (None, 14, 14, 256) 590080
_________________________________________________________________
batch_normalization_1 (Batch (None, 14, 14, 256) 1024
_________________________________________________________________
re_lu (ReLU) (None, 14, 14, 256) 0
_________________________________________________________________
conv2d_transpose_1 (Conv2DTr (None, 14, 14, 128) 295040
_________________________________________________________________
batch_normalization_2 (Batch (None, 14, 14, 128) 512
_________________________________________________________________
re_lu_1 (ReLU) (None, 14, 14, 128) 0
_________________________________________________________________
conv2d_transpose_2 (Conv2DTr (None, 28, 28, 64) 73792
_________________________________________________________________
batch_normalization_3 (Batch (None, 28, 28, 64) 256
_________________________________________________________________
re_lu_2 (ReLU) (None, 28, 28, 64) 0
_________________________________________________________________
conv2d_transpose_3 (Conv2DTr (None, 28, 28, 1) 577
_________________________________________________________________
activation (Activation) (None, 28, 28, 1) 0
=================================================================
Total params: 2,278,401
Trainable params: 2,252,417
Non-trainable params: 25,984
_________________________________________________________________
약 228만개의 parameters를 갖는 것을 볼 수 있으며 우리의 target data mnist data의 shape과 동일한 (28, 28, 1)의 이미지를 만들어냅니다.
Results of Discriminator
Model: "discriminator_mnist"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 13, 13, 128) 1280
_________________________________________________________________
leaky_re_lu (LeakyReLU) (None, 13, 13, 128) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 6, 6, 256) 295168
_________________________________________________________________
batch_normalization_4 (Batch (None, 6, 6, 256) 1024
_________________________________________________________________
leaky_re_lu_1 (LeakyReLU) (None, 6, 6, 256) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 3, 3, 512) 2097664
_________________________________________________________________
batch_normalization_5 (Batch (None, 3, 3, 512) 2048
_________________________________________________________________
leaky_re_lu_2 (LeakyReLU) (None, 3, 3, 512) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 2, 2, 1024) 8389632
_________________________________________________________________
batch_normalization_6 (Batch (None, 2, 2, 1024) 4096
_________________________________________________________________
leaky_re_lu_3 (LeakyReLU) (None, 2, 2, 1024) 0
_________________________________________________________________
conv2d_4 (Conv2D) (None, 2, 2, 1) 16385
_________________________________________________________________
flatten (Flatten) (None, 4) 0
_________________________________________________________________
dense_1 (Dense) (None, 1) 5
=================================================================
Total params: 10,807,302
Trainable params: 10,803,718
Non-trainable params: 3,584
_________________________________________________________________
discriminator는 입력으로 (batch size, 28, 28, 1) 크기의 데이터를 받습니다. dense layer를 통해 출력값을 얻었습니다. 전체 parameter 수는 약 1081만개 입니다.
Optimizer - Adam
Optimizer로는 논문의 Algorithm과 동일하게 Adam을 사용하였으며 Adam의 learning rate와 hyperparameters $\beta$1, $\beta$2 는 각각 0.0001, 0, 0.9를 사용했습니다.
# Set optimizer
generator_optimizer = keras.optimizers.Adam(learning_rate, beta_1 = b_1, beta_2 = b_2)
discriminator_optimizer = keras.optimizers.Adam(learning_rate, beta_1 = b_1, beta_2 = b_2)
seed 고정과 결과 이미지 생성
처음에 결과 이미지를 확인하기 위해 변수 num_examples_to_generate를 16(4*4)로 정의해두었습니다. 고정된 seed에 대해 결과 이미지가 변해가는 과정을 보기 위해서 다음과 같이 seed를 만들어줍니다.
seed = tf.random.normal([num_examples_to_generate, noise_dim])
이렇게 만들어 놓은 seed를 사용해 결과화면에 4X4 형태로 보여주고 저장을 하려고 합니다. 결과 이미지가 저장되는 경로는 plt.savefig()의 인자에 명시된 results/ 폴더에 저장됩니다.
def generate_and_save_images(model, epoch, test_input):
predictions = model(test_input)
fig = plt.figure(figsize=(4,4))
for i in range(predictions.shape[0]):
plt.subplot(4, 4, i+1)
# mnist
plt.imshow(predictions[i, :, :, 0] * 0.5 + 0.5, cmap='gray')
plt.axis('off')
plt.savefig('results/image_at_epoch_{:04d}.png'.format(epoch))
plt.show()
Checkpoint Setting
학습 중간중간 일정 epoch마다 모델을 저장하기 위해 checkpoint를 setting합니다.
checkpoint_dir = './training_checkpoints'
checkpoint_prefix = os.path.join(checkpoint_dir, "ckpt")
checkpoint = tf.train.Checkpoint(generator_optimizer=generator_optimizer,
discriminator_optimizer=discriminator_optimizer,
G=G,
D=D)
Train step function & Loss
이번 WGAN-GP 논문구현에서는 이전의 WGAN 구현과 다르게 따로 loss function을 함수로 만들지 않고 각 네트워크의 학습 step안에 정의했습니다.
우선 Discriminator step 먼저 설명하겠습니다. 설명드릴 코드는 [for t = 1,…,$n$$critic$ do … end for] 내의 for loop부터 weight update까지의 내용이며 Algorithm1 일부를 캡처한 부분입니다. $n$$critic$번 학습시키는 코드는 train 함수 내에 구현되어 있습니다.
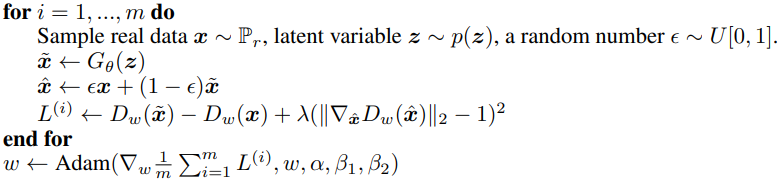
논문의 저자는 batch norm을 critic의 single input -> single output 맵핑 문제를 batch inputs -> batch outputs로 바꾸는 문제가 있으며 각 입력에 대해 독립적으로 penalty를 가하기 위해 사용하지 않았습니다. 물론 알고리즘 상에서도 나타나 있습니다.
하지만 코드 상에서는 batch에 대해 for loop를 더 사용하지 않고 이미지 tensor의 제일 앞에 차원을 추가해 개별적인 penalty를 가함에는 변함이 없도록 하였습니다.
우선 $x$는 real data distribution에서 추출한 sample이며 images의 image batch 입니다.
$\tilde{x}$ $\gets$ $G$$\theta$($z$) 는 noise를 입력으로 G가 만들어낸 fake images로 코드상 generated_images = G(noise)에 해당합니다.
$\hat{x}$ $\gets$ $\epsilon$$x$ + (1 - $\epsilon$)$\tilde{x}$ 는 sample $x$와 $\tilde{x}$의 내분점입니다. 이때 $\epsilon$은 tf.random.uniform(shape=[len_batch, 1, 1, 1])로 얻어진 random number입니다.
Loss term을 보면 $L$$(i)$ $\gets$ $D$$w$($\tilde{x}$) - $D$$w$($x$) + $\lambda$( $\lVert$ $\nabla$$\hat{x}$$D$$w$($\hat{x}$) $\rVert$2 - 1 )2 이며 앞의 $D$$w$($\tilde{x}$) - $D$$w$($x$) 는 WGAN loss function과 동일하며 disc_loss = K.mean(fake_output) - K.mean(real_output) 로 계산됩니다.
이제 Gradient Penalty term $\lambda$( $\lVert$ $\nabla$$\hat{x}$$D$$w$($\hat{x}$) $\rVert$2 - 1 )2 을 하나씩 보며 설명하겠습니다. 우선 앞서 선언한 eps를 통해 x_hat : $\epsilon$$x$ + (1 - $\epsilon$)$\tilde{x}$를 구하면 eps*images + (1 - eps)*generated_images가 됩니다.
tensorflow의 GradientTape()을 이용해 gradient $\nabla$$\hat{x}$$D$$w$($\hat{x}$) 를 구합니다. 해당하는 부분의 코드는 아래와 같습니다.
with tf.GradientTape() as t:
t.watch(x_hat)
d_hat = D(x_hat)
gradients = t.gradient(d_hat, [x_hat])
코드는 텐서플로우 공식 홈페이지에서 자세히 알 수 있습니다.
간단히 설명을 하면 t.gradient(d_hat, [x_hat])는 x_hat에 대한 도함수를 구하는 코드입니다.
이후에 l2_norm을 K.sqrt(K.sum(K.square(gradients), axis=[2,3]))로 구할 수 있으며 이때 K.sum()의 axis=[2,3]인 이유는 각 batch에 해당하는 축과 이미지의 채널에 해당하는 축을 제외한 2차원에 대해서 norm을 구하기 위해서 입니다. 그 이후에 K.squeeze(l2_norm, axis=0)처럼 squeeze를 통해 차원을 하나 줄이는데 그 이유는 입력 l2_norm의 차원이 (1, batch, 1)로 들어오기 때문에 (batch, 1)로 만들기위해 사용합니다.
그리고 gradient_penalty = K.sum(K.square((l2_norm-1.)), axis=[1])를 통해 1을 빼고 제곱을 했던 최종적인 penalty를 구할 수 있으며 $\lambda$를 곱해주고 기존의 wgan loss에 더해줘 최종적으로 disc_loss += gp_lambda*gradient_penalty로 구현할 수 있습니다.
Discriminator step
def discriminator_train_step(images):
len_batch = len(images) # 마지막 batch에서의 length를 맞춰주기 위함
noise = tf.random.normal([len_batch, noise_dim])
with tf.GradientTape() as disc_tape:
D.training = True
generated_images = G(noise)
real_output = D(images)
fake_output = D(generated_images)
#wgan loss
disc_loss = K.mean(fake_output) - K.mean(real_output)
eps = tf.random.uniform(shape=[len_batch, 1, 1, 1])
x_hat = eps*images + (1 - eps)*generated_images
with tf.GradientTape() as t:
t.watch(x_hat)
d_hat = D(x_hat)
gradients = t.gradient(d_hat, [x_hat]) # gradients 계산
l2_norm = K.sqrt(K.sum(K.square(gradients), axis=[2,3]))
l2_norm = K.squeeze(l2_norm, axis=0)
gradient_penalty = K.sum(K.square((l2_norm-1.)), axis=[1])
disc_loss += gp_lambda*gradient_penalty
gradients_of_discriminator = disc_tape.gradient(disc_loss, D.trainable_variables)
discriminator_optimizer.apply_gradients(zip(gradients_of_discriminator, D.trainable_variables))
return K.sum(disc_loss)
Generator step
Generator의 경우 Discriminator에 비해 비교적 간단하게 구현할 수 있으며 단지 WGAN loss term만 있으면 됩니다. 따라서 gen_loss = - K.mean(fake_output)로 간단히 loss를 구하고 optimizer를 통해 train step을 진행할 수 있습니다.
def generator_train_step(images):
noise = tf.random.normal([batch_size, noise_dim])
with tf.GradientTape() as gen_tape:
G.training = True
generated_images = G(noise)
fake_output = D(generated_images)
#wgan loss
gen_loss = - K.mean(fake_output)
gradients_of_generator = gen_tape.gradient(gen_loss, G.trainable_variables)
generator_optimizer.apply_gradients(zip(gradients_of_generator, G.trainable_variables))
return K.sum(gen_loss)
Training
train 함수에서는 dataset과 epochs 값을 입력으로 받아 정해놓은 epoch 값 만큼 학습을 진행합니다. batch마다 얻어진 loss 값을 list에 담고 전체 epoch에 대한 평균 loss를 출력합니다. critic의 경우 generator 학습 이전에 먼저 $n$critic번 for loop를 통해 학습하고 loss는 $n$critic로 나눠줘 평균을 취해줍니다. 그리고 한 epoch이 끝나면 4x4 형태로 결과를 plot하고 저장합니다. 또한 주석처리된 if문 내의 K에 적절한 값을 넣어 K epochs 마다 checkpoint에 모델을 저장할 수 있습니다.
def train(dataset, epochs):
for epoch in range(epochs):
start = time.time()
gen_loss_list = []
disc_loss_list = []
for image_batch in train_dataset:
loss_d = 0
for i in range(n_critic):
loss_d += discriminator_train_step(image_batch)
loss_g = generator_train_step(image_batch)
gen_loss_list.append(loss_g)
disc_loss_list.append(loss_d / n_critic)
# 이미지 생성
display.clear_output(wait=True)
generate_and_save_images(G, epoch + 1, seed)
# K epochs 지날 때마다 모델 저장
if (epoch + 1) % K == 0:
checkpoint.save(file_prefix = checkpoint_prefix)
# loss & 시간 출력
print ('Time for epoch {} is {} sec'.format(epoch + 1, time.time()-start))
print ('G_Loss is {}, D_Loss is {}'.format(sum(gen_loss_list)/len(gen_loss_list),
sum(disc_loss_list)/len(disc_loss_list)))
# 학습이 끝난 후 이미지 생성
display.clear_output(wait=True)
generate_and_save_images(G, epochs, seed)
저는 학습을 가상환경의 jupyter notebook에서 진행했습니다.
jupyter cell에서
%%time
train(train_dataset, epochs)
다음 코드를 실행시키면 학습을 진행할 수 있습니다.
Results
다음은 WGAN-GP를 통해 얻은 mnist data 결과입니다. 놀랍게도 1 epoch만에 숫자를 만들어 냈으며 이후로 점차 선명하고 진한 숫자를 만들어냈습니다. 학습은 약 50 epochs을 진행하였고 각 epoch에 대한 결과를 통해 만들어진 gif 입니다.
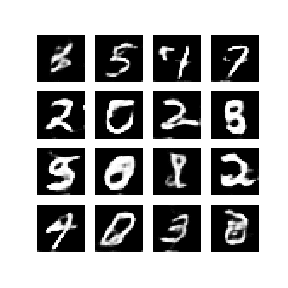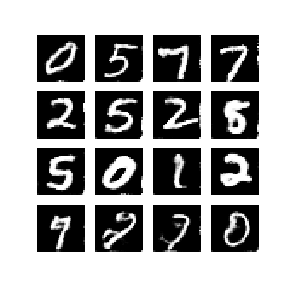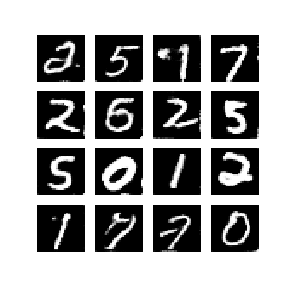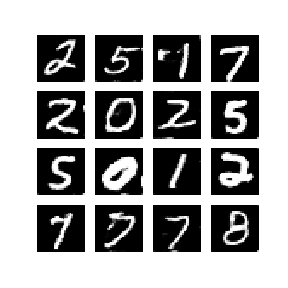
Dependencies
OS : Ubuntu 18.04
GPU : RTX2080ti
CUDA : 10.0
CUDNN : 7.6
-------------------------
python : 3.7.4
tensorflow : 2.0.0-gpu
keras : 2.2.4-tf
numpy : 1.17.0
matplotlib : 3.1.1
Reference
- WGAN-GP 논문 - https://arxiv.org/abs/1704.00028
- 케라스 공식 홈페이지 - https://keras.io/
- 텐서플로우 공식 홈페이지 - https://www.tensorflow.org/api_docs
GAN에 대한 Tensorflow 구현을 차근차근 올리도록하겠습니다. 구현에 이상이 있거나 궁금한 내용은 편하게 댓글 달아주세요. 감사합니다.
댓글남기기